
数据可视化–Matplotlib
应用介绍
在解决机器学习问题时,常常用Matplotlib可视化分析数据结果,它是是用于可视化的最受欢迎的Python库通常仅仅依靠数据很难得出结论性的东西,通过可视化就数据以图表形式呈现,能够直观的进行数据对比,容易得出结论,方便与分析问题.
折线图|ax.plot(x,y)
它有助于根据给定范围的定义参数表示一系列数据点。 真正的好处是在单个图中绘制多个折线图,以比较和跟踪变化。
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(0, 1, 0.05)
y1 = x**2
y2 = x**3
plt.plot(x, y1,
linewidth=0.5,
linestyle='--',
color='b',
marker='o',
markersize=10,
markerfacecolor='red')
plt.plot(x, y2,
linewidth=0.5,
linestyle='dotted',
color='g',
marker='^',
markersize=10,
markerfacecolor='yellow')
plt.title('x Vs f(x)')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.legend(['f(x)=x^2', 'f(x)=x^3'])
plt.xticks(np.arange(0, 1.1,0.2),
['0','0.2','0.4','0.6','0.8','1.0'])
plt.grid(True)
plt.show()

真实的例子
我们将使用通过整理从此处下载的几只股票的历史数据而创建的数据集。
import pandas as pd
import matplotlib.pyplot as plt
stocksdf1 = pd.read_csv('data-files/stock-INTU.csv')
stocksdf2 = pd.read_csv('data-files/stock-AAPL.csv')
stocksdf3 = pd.read_csv('data-files/stock-ADBE.csv')
stocksdf = pd.DataFrame()
stocksdf['date'] = pd.to_datetime(stocksdf1['Date'])
stocksdf['INTU'] = stocksdf1['Open']
stocksdf['AAPL'] = stocksdf2['Open']
stocksdf['ADBE'] = stocksdf3['Open']
plt.plot(stocksdf['date'], stocksdf['INTU'])
plt.plot(stocksdf['date'], stocksdf['AAPL'])
plt.plot(stocksdf['date'], stocksdf['ADBE'])
plt.legend(labels=['INTU','AAPL','ADBE'])
plt.grid(True)
plt.show()
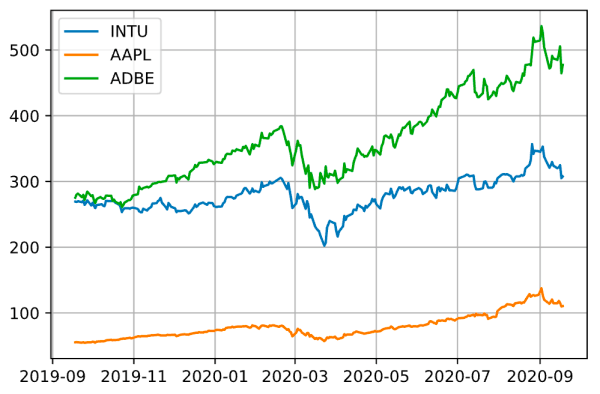
通过以上内容,我们可以进行一些快速评估:
问:去年某只股票表现如何?
答:到2020年2月,股票大致在上涨,然后在4月下跌,此后又回升。
问:三只股票在同一时期表现如何?
答:同一时期,ADBE的股价更敏感,而AAPL的股价最不敏感。
直方图| ax.hist(data, n_bins)
它有助于显示变量的分布,在其中绘制定量数据并按范围将数据范围分组。
引用:
如果数据范围跨越几个数量级,我们可以使用对数刻度。
import numpy as np
import matplotlib.pyplot as plt
mean = [0, 0]
cov = [[2,4], [5, 9]]
xn, yn = np.random.multivariate_normal(
mean, cov, 100).T
plt.hist(xn,bins=25,label="Distribution on x-axis");
plt.xlabel('x')
plt.ylabel('frequency')
plt.grid(True)
plt.legend()
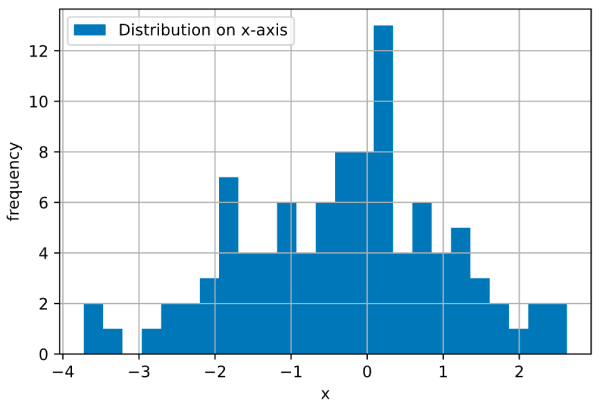
真实的例子
我们将处理从此处下载的印度人口普查数据的数据集。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
populationdf = pd.read_csv(
"./data-files/census-population.csv")
mask1 = populationdf['Level']=='STATE'
mask2 = populationdf['TRU']=='Total'
df = populationdf[mask1 & mask2]
plt.hist(df['TOT_P'], label='Distribution')
plt.xlabel('Total Population')
plt.ylabel('State Count')
plt.yticks(np.arange(0,20,2))
plt.grid(True)
plt.legend()
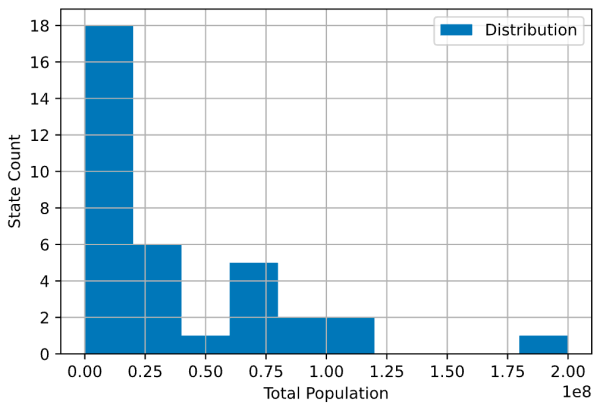
通过以上内容,可以对印度各州的人口进行一些快速评估:
问:印度各州的总体人口分布是什么?
答:超过50%的州人口不到2亿(2000万)
问:有多少州的人口超过1亿(1亿)?
答:只有3个州的人口众多。
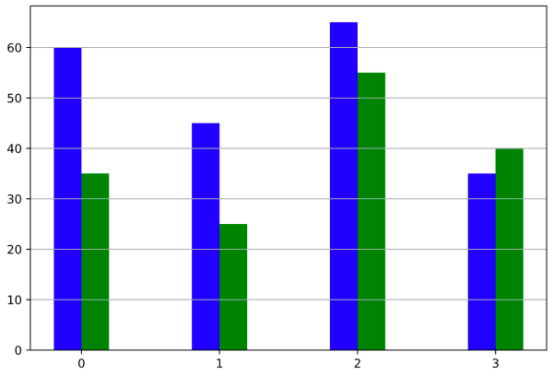
条形图| ax.bar(x_pos, heights)
通过显示与分类数据关联的值,它有助于比较两个或多个变量。
引用:
媒体中最常用的绘图,在围绕显示每个数据样本的调查共享数据
import numpy as np
import matplotlib.pyplot as plt
data = [[60, 45, 65, 35],
[35, 25, 55, 40]]
x_pos = np.arange(4)
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.set_xticks(x_pos)
ax.bar(x_pos - 0.1, data[0], color='b', width=0.2)
ax.bar(x_pos + 0.1, data[1], color='g', width=0.2)
ax.yaxis.grid(True)
真实的例子
我们将处理从此处下载的印度人口普查数据的数据集。
import pandas as pd
import matplotlib.pyplot as plt
populationdf = pd.read_csv(
"./data-files/census-population.csv")
mask1 = populationdf['Level']=='STATE'
mask2 = populationdf['TRU']=='Total'
statesdf = populationdf.loc[mask1].loc[mask2]
statesdf = statesdf.sort_values('TOT_P')
plt.figure(figsize=(10,8))
plt.barh(range(len(statesdf)),
statesdf['TOT_P'], tick_label=statesdf['Name'])
plt.grid(True)
plt.title('Total Population')
plt.show()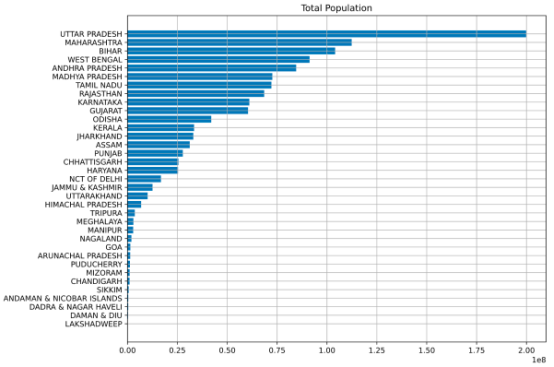
通过以上内容,可以对印度各州的人口进行一些快速评估:
北方邦的总人口最多,而拉克沙迪普的总人口最少
北方邦各州的相对人口密度几乎是第二高人口州的两倍
饼形图| ax.pie(sizes, labels=[labels])
它有助于显示类别在特定时间点的百分比(或比例)分布。 通常,如果仅限一位数类别,则效果很好。
引用:
圆形统计图形,其中每个切片的弧长与其表示的量成比例。
import numpy as np
import matplotlib.pyplot as plt
# Slices will be ordered n plotted counter-clockwise
labels = ['Audi','BMW','LandRover','Tesla','Ferrari']
sizes = [90, 70, 35, 20, 25]
fig, ax = plt.subplots()
ax.pie(sizes,labels=labels, autopct='%1.1f%%')
ax.set_title('Car Sales')
plt.show()

真实的例子
我们将处理从此处下载的酒精消耗数据集。
import panda as pd
import matplotlib.pyplot as plt
drinksdf = pd.read_csv('data-files/drinks.csv',
skiprows=1,
names = ['country', 'beer', 'spirit',
'wine', 'alcohol', 'continent'])
labels = ['Beer', 'Spirit', 'Wine']
sizes = [drinksdf['beer'].sum(),
drinksdf['spirit'].sum(),
drinksdf['wine'].sum()]
fig, ax = plt.subplots()
explode = [0.05,0.05,0.2]
ax.pie(sizes,explode=explode,
labels=labels, autopct='%1.1f%%')
ax.set_title('Alcohol Consumption')
plt.show()
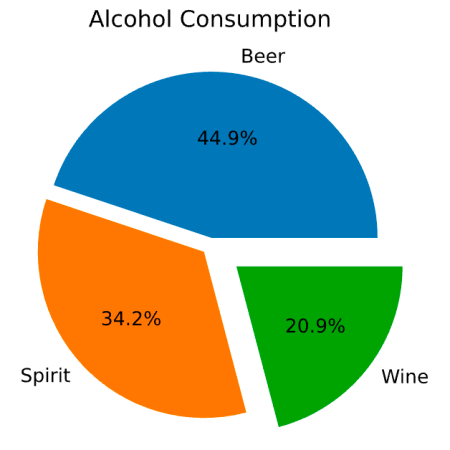
通过以上内容,我们可以快速评估酒精的消费量是否总体分布。 如果我们数量较少,此视图会有所帮助。
3-D绘图
如果需要,我们也可以使用交互式3-D图,尽管对于大型数据集而言可能会很慢。
import numpy as np
import matplotlib.pyplot as plt
def randrange(n, vmin, vmax):
return (vmax-vmin)*np.random.rand(n) + vmin
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(111, projection='3d')
n = 200
for c, m, zl in [('g', 'o', +1), ('r', '^', -1)]:
xs = randrange(n, 0, 50)
ys = randrange(n, 0, 100)
zs = xs+zl*ys
ax.scatter(xs, ys, zs, c=c, marker=m)
ax.set_xlabel('X data')
ax.set_ylabel('Y data')
ax.set_zlabel('Z data')
plt.show()
©版权声明:本文内容由互联网用户自发贡献,版权归原创作者所有,本站不拥有所有权,也不承担相关法律责任。如果您发现本站中有涉嫌抄袭的内容,欢迎发送邮件至: www_apollocode_net@163.com 进行举报,并提供相关证据,一经查实,本站将立刻删除涉嫌侵权内容。
转载请注明出处: apollocode » 数据可视化–Matplotlib
文件列表(部分)
| 名称 | 大小 | 修改日期 |
|---|---|---|
| data-visualization | 0.00 KB | 2020-10-18 |
| data-files | 0.00 KB | 2020-10-48 |
| accident-data.csv | 2.50 KB | 2020-10-48 |
| BabyGroot.jpg | 29.42 KB | 2020-10-48 |
| census-population.csv | 352.97 KB | 2020-10-48 |
| drinks.csv | 5.78 KB | 2020-10-48 |
| mall-customers.csv | 3.69 KB | 2020-10-48 |
| prog-languages.csv | 0.47 KB | 2020-10-48 |
| stock-AAPL.csv | 17.76 KB | 2020-10-48 |
| stock-ADBE.csv | 18.40 KB | 2020-10-48 |
| stock-INTU.csv | 18.33 KB | 2020-10-48 |
| tips.csv | 9.50 KB | 2020-10-48 |
| matplotlib-additionalusage.ipynb | 475.64 KB | 2020-10-48 |
| matplotlib-basic.ipynb | 2,690.08 KB | 2020-10-48 |
| matplotlib-examples.ipynb | 972.10 KB | 2020-10-48 |
| matplotlib-presentation.ipynb | 332.47 KB | 2020-10-48 |
| probability-distribution.ipynb | 233.12 KB | 2020-10-48 |

发表评论 取消回复